
Modern video translation technologies have reached new levels of realism thanks to neural network-powered lip synchronization. This process, known as lip sync, enables translated videos where lip movements perfectly match the new audio track. 🤖💬
What is AI Lip Sync and How It Works
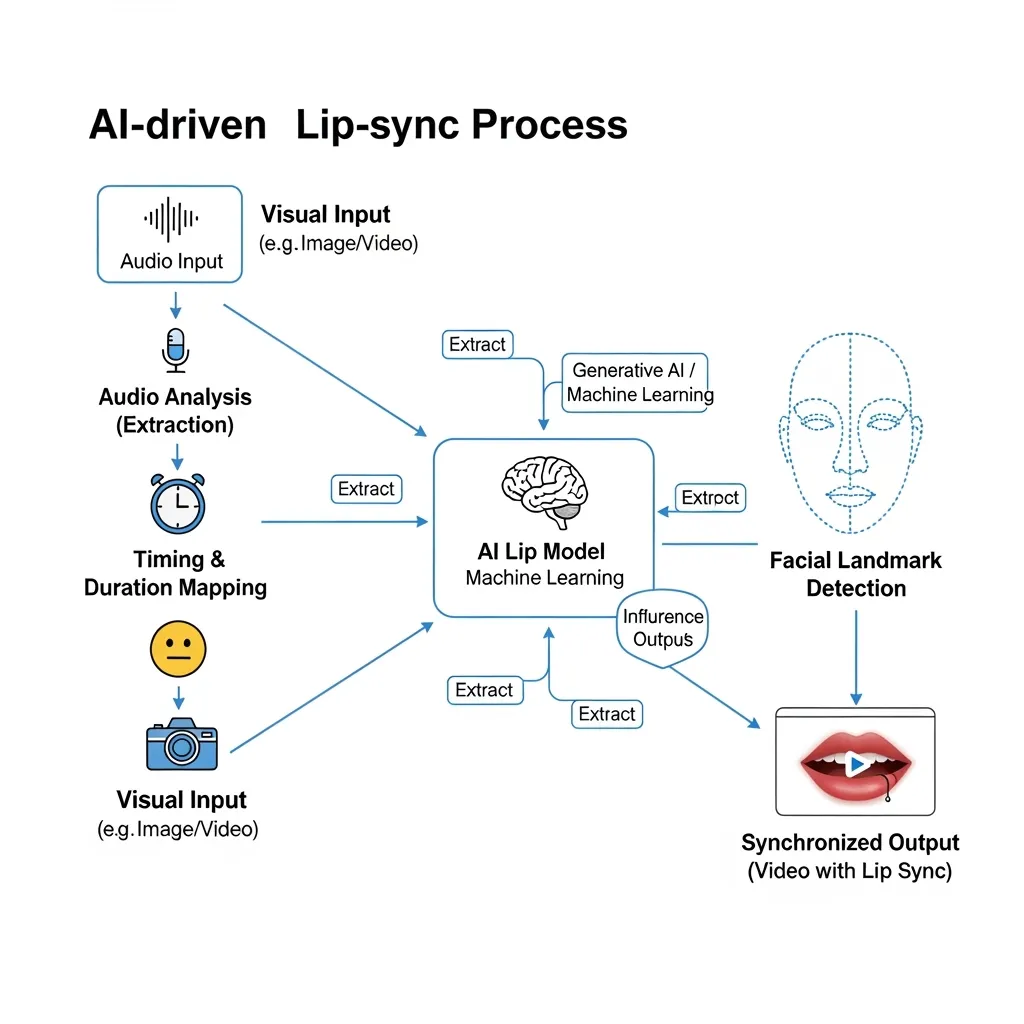
AI-powered lip sync is a technology that automatically synchronizes lip movements in video with an audio track by analyzing sound signals and generating corresponding facial expressions. Unlike traditional dubbing where mismatched articulation is noticeable, AI lip sync creates the illusion that the person is actually speaking the new language.
Technology Principles
Modern lip sync algorithms like Wav2Lip use deep learning to analyze the relationship between audio signals and facial movements. The process involves several key stages:
- Phoneme recognition - the neural network analyzes the audio track, identifying individual phonemes and their time boundaries. Each phoneme corresponds to specific lip and tongue positions.
- Facial analysis - the system detects facial landmarks in the video including lip contours, jaw position and other articulatory features.
- Synchronization generation - the algorithm creates new video frames where lip movements precisely match phonemes from the audio track while maintaining natural facial expressions.
Without lip sync: noticeable mismatch
With lip sync: natural synchronization
Modern Model Architecture
Core Principles of Lip Sync Neural Networks
Most modern solutions are based on Generative Adversarial Networks (GANs) and transformers. The model consists of several components:
- Audio encoder - converts sound signals into feature representations
- Video encoder - extracts facial visual features from source video
- Generator - creates new frames with synchronized lip movements
- Discriminator - evaluates realism of generated frames
Temporal Dependency Processing
A key feature of effective models is accounting for temporal context. The system analyzes not just current sounds but also preceding/subsequent phonemes to create smooth transitions between lip positions.
Proven Effectiveness in Numbers
Companies using AI lip-sync report a 10x increase in content completion rates and 200-400% audience growth. The Forecast platform reduced course creation time by 50%, while the media company Insider gained 100 million views within weeks of localization. The lip-sync technology market grew to $1.12 billion in 2024, with a projected $5.76 billion by 2034. Furthermore, 60% of Fortune 100 companies have already implemented this technology.
Recommendations for High-Quality Lip Sync
Source Material Preparation
Video quality is critical. For best results we recommend:
For optimal lip sync quality in video translation, use AI dubbing. Learn more about AI dubbing technologies →
- Use video with minimum 720p resolution
- Ensure good facial lighting without harsh shadows
- Select frames where the face is front-facing to camera
- Avoid excessive head movements and exaggerated lip articulation as well as sharp turns
Optimal Audio Parameters
Synchronization quality directly depends on the audio track:
- Clean speech without background noise or music
- Consistent pace of pronunciation
- Clear articulation - avoid "swallowing" sounds
Popular Solutions Comparison
| Service | Features | Limitations |
|---|---|---|
| Speeek.io | 20+ language support, voice cloning, processing videos up to 2 hours | Free version available |
| HeyGen | 40+ language support, voice cloning | Paid subscription |
| Wav2Lip | Open-source, high accuracy | Requires technical skills |
| LipDub AI | Professional quality | High cost |
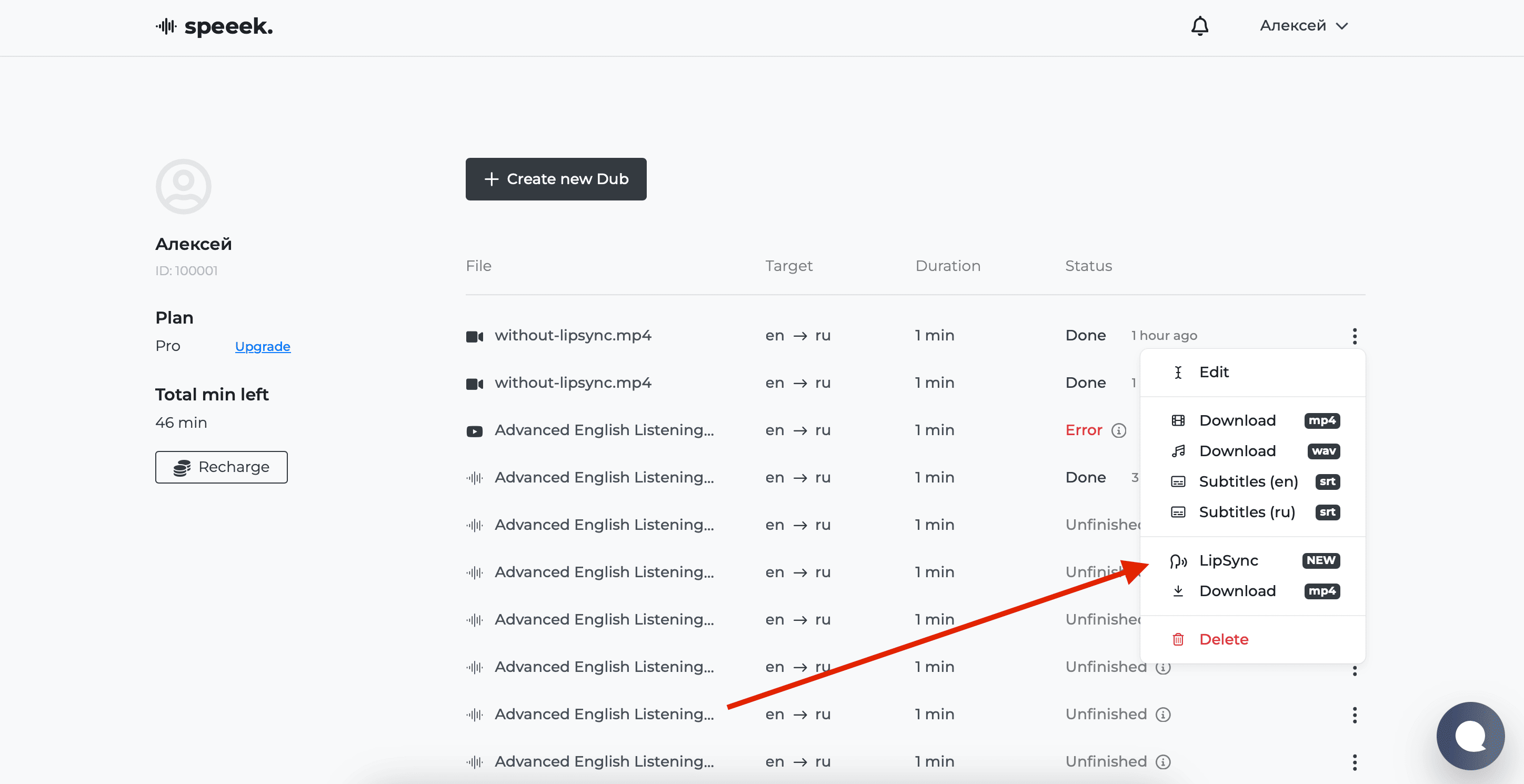
Creating Lip Sync on Speeek.io
Our service speeek.io offers professional tools for creating synchronized video translations with cutting-edge lip sync algorithms.
Step-by-step process:
- Upload material - select a video file from your device or provide a video link. The system automatically detects duration and source quality.
- Select translation language - choose from 20+ target languages. The system supports popular language pairs including English, Spanish, Chinese and others.
- Configure parameters - define voice settings (male/female voice), number of speakers etc. Advanced plans offer additional synchronization quality parameters.
- Processing and generation - our servers handle speech translation, new voice generation. The process typically takes 2-5 minutes depending on video length.
- Final LipSync - use lip synchronization as the final step after making all edits to the translation.
When Not to Use Lip Sync
Technical Limitations
There are situations where lip sync may produce unsatisfactory results:
Complex facial expressions
With strong emotions the system may distort natural facial expressions
Non-human characters
Models perform poorly with animated characters or animals
Multiple speakers
Quality decreases with several people in frame
Ethical Considerations
Important!
Potential for misinformation - the technology could be used to create fake news and deepfakes. According to MIT 2024 research, 68% of viewers can't distinguish professional AI lip sync from real video.
Participant consent - when working with videos of real people, their consent for image processing must be obtained.
Future of the Technology
AI lip sync development continues at rapid pace. Here are expected breakthroughs in coming years:
Emotional intelligence
Models will learn to accurately convey complex emotional states
Real-time processing
Synchronization delay will reduce to 100-200 ms
Full integration
The technology will become standard in video editors and streaming platforms
Conclusion
Lip sync technology is already transforming the content industry, making video globalization accessible to creators at all levels. Understanding how it works and its limitations will help effectively leverage its capabilities for your creative and business goals.